
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 자기개발
- 독학
- streamlit
- ssafy 13기
- matacodem
- ML
- SSAFY
- JLPT
- 부트캠프
- DS
- 데이터 엔지니어
- 데이터분석가
- 데이터 사이언티스트
- 데이터사이언티스트
- 자기계발
- 데이터애널리스트
- 개발자부트캠프
- 데이터전문가
- 싸피
- 오블완
- 티스토리챌린지
- 일본어공부
- 머신러닝
- 메타코드
- 데이터엔지니어
- metacode
- 데이터분석
- metacodem
- 파이썬
- 메타코드m
Archives
- Today
- Total
아카이브
[Apache Spark] 스파크에 대해 알아보자 + 파이썬 스파크 설치 [임시] 본문
데이터를 추출할 때 우리는 도서관에 가는 상황과 유사하다.
책장에 너무 많은 책들이 있고 우리는 이걸 일일히 책장에 도달해 책을 찾고 꺼내온다.
이 과정에서 속도 개선이 필요하기에 메모리(간이 책장)을 만들어 시간을 줄이고자 하는 것이 Aparche Spark되시겠다!
아파치 스파크란? 인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크
기존 Hadopp MapReduce의 문제점
- 부하가 심하고 속도가 느림 - 처리과정마다 HDD 거쳐 공유
- MapReduce 프로그래밍은 어렵고 복잡
Spark 적용 환경
- 환경: Hadoop, Mesos, stand alone, cloud
- Data sources: HDFS, Cassandra, Hbase, Hive, Tachyon, any Hadoop dat
Spark 설치 해봅시다.
https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
해당 링크에서 다운받으실 수 있어요

1. 버전 설정
2. 패키지 타입 그대로 했습니다.
3. tgz 다운 받아요 오래걸립니다.
경로 설정에 관해서는 다음에.. 자세히 다뤄볼게요.
하둡 - 스파크 - R 연동이 가능한데
저는 파이썬에서 스파크를 실행하는 것을 목표로
한 번 해볼게요.
1. 파이스파크 설치 PyPi
pip install pyspark패키지 설치하는데 4분정도 걸렸어요.
2. 설치 잘 됐는지 확인
import os
import sys
try:
from pyspark import SparkContext
from pyspark import SparkConf
print("Successfully imported Spark Modules")
except ImportError as e:
print("Can not import Spark Modules",e)
sys.exit(1)해당 코드 실행해주시고
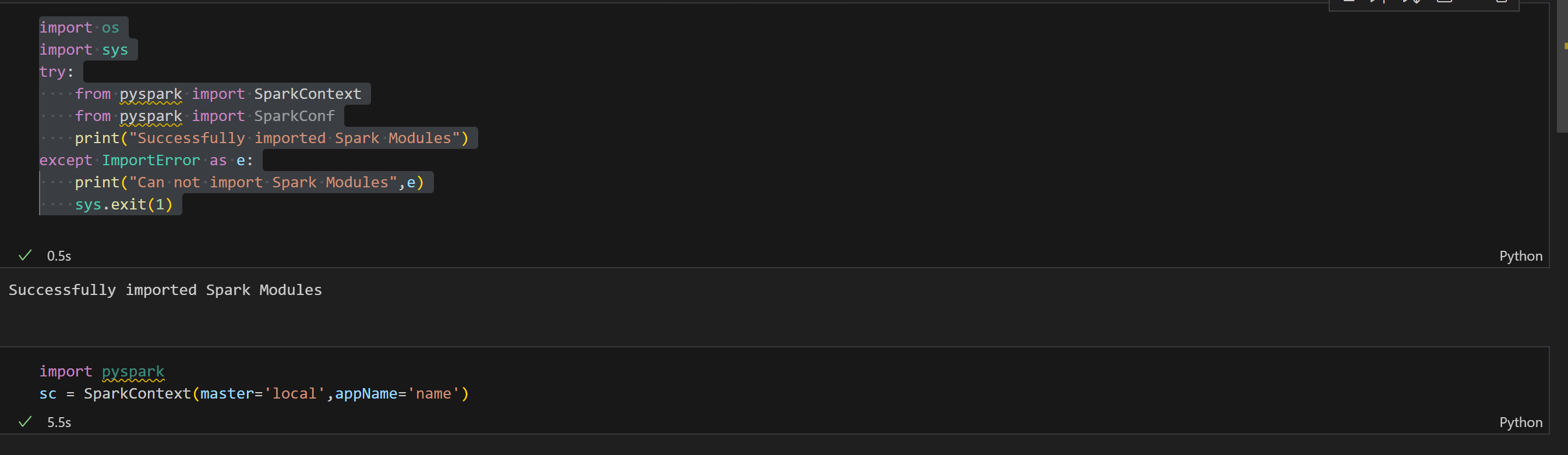
요래뜨면 잘 된겁니다!
'데이터 엔지니어' 카테고리의 다른 글
| [Hadoop] 하둡에 대해 알아보자 (3) | 2024.11.07 |
|---|
'데이터 엔지니어' Related Articles
more
