

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- DS
- 데이터전문가
- 데이터분석가
- 데이터 엔지니어
- ML
- 개발자부트캠프
- 데이터분석
- 데이터사이언티스트
- 일본어공부
- metacodem
- 부트캠프
- metacode
- streamlit
- ssafy 13기
- 자기계발
- JLPT
- 메타코드
- 데이터 사이언티스트
- 데이터애널리스트
- 독학
- 자기개발
- 데이터엔지니어
- 티스토리챌린지
- SSAFY
- 오블완
- 머신러닝
- 메타코드m
- 파이썬
- matacodem
- 싸피
- Today
- Total
아카이브
[데이터 사이언티스트] kaggle 데이터를 활용한 실전 머신러닝 | IT기업 Data Scientist 현직자 (4) 본문
[데이터 사이언티스트] kaggle 데이터를 활용한 실전 머신러닝 | IT기업 Data Scientist 현직자 (4)
머루아빠승우 2024. 10. 13. 23:31kaggle 데이터를 활용한 실전 머신러닝 4차시입니다.
데이터 분석 직무를 희망하게 된 저는
주변에서 다들 데이터 분석하면 캐글 플젝 한 번 해봐야지~
라는 이야기를 듣곤 했어요.
실제로 관련 프로젝트로 좋은 학습의 기회를 경험했다는 소식을 듣곤
나도 언젠간 한 번 해봐야지라는 생각이 있었습니다.

그리고 메타코드 앰배서더가 되어 좋은 기회로
관련 강의를 듣게 될 수 있어 현재 수강 중입니다~
Kaggle을 통한 시계열 데이터 분석 + 머신러닝 학습을 희망하는 분들은
제 게시글을 보시고 메타코드에서 한 번 성장해보심 어떨까요?
메타코드M
AI 강의 & 커뮤니티 플랫폼ㅣ300만 조회수 기록한 IT 현직자들의 교육과 함께 하세요
metacodes.co.kr
현재 진도!

아~ 2주차 완료입니다.
꾸준히 학습하고 기록으로도 남기니 더 열심히
하게 되는 것 같아요.
현재 기초적인 EDA 이후 ML을 본격적으로 다뤄보고 있습니다.
더불어, FE(Featuer Enginnering)과 Post Processing 과정을 통해
모델 성능을 높이는 방법까지 학습해볼 수 있었습니다.
서론이 길네요 ㅎㅎ
상세한 강의 내용과 함께 리뷰 내용 시작합니다!
예측 방법론 개요
kaggle 데이터를 활용한 실전 머신러닝 | IT기업 Data Scientist 현직자
metacodes.co.kr
크게 시계열 알고리즘과 ML 모델(+딥러닝)을 이용한 알고리즘으로 구분되요.
시계열 알고리즘
- 자기상관 y 값을 활용하여 과거 (t-1..t-n) 패턴을 학습하여 미래 예측
- ML 모델처럼 Feature 정보를 활용하지 않으므로 간편하나
- 정확도는 ML 모델에 비해 낮은 경향
- 대표적인 알고리즘으로 [Prophet](https://hyperconnect.github.io/2020/03/09/prophet-package.html),
[ARIMA](https://dong-guri.tistory.com/9),
[Exponential Smoothing](https://aiemag.tistory.com/260)
M/L 알고리즘
- Feature Engineering을 통한 모델 학습 및 예측 수행
- target y 값을 잘 설명하는 변수를 선정하여 모델 학습시키면 정확도 높은 경향
- 단, Feature 의 퀄리티에 따라 성능이 영향을 받음
- 대표적인 알고리즘으로 [Linear Regression, Ridge, Lasso](https://hye-z.tistory.com/22),
[Tree-based: Random Forest, LGBM, XGBOOST](https://sikmulation.tistory.com/18),
[MLP](https://m.blog.naver.com/samsjang/221030487369) 등
해당 강의는 위 두 케이스를 가지고 실제 데이터를 가지고 머신 러닝 모델을 돌려
데이터 사이언티스트로서 인사이트를 뽑아보는 프로젝트입니다.
이렇게 실제 ML에 쓰이는 라이브러리를 import해서
싸이킷런을 가지고 가벼운 ML 모델을 이용해보는 실습 프로젝트입니다.
익히 쓰는 XGBOOST, RF, Regreesor, LGBM 등
기본적으로 데이터 사이언티스를 희망하는 여러분께서는
그리 낯선 모델이 아닐 거라고 생각이 듭니다.

제가 해당 강의를 보면서 좀 좋다고 생각했던 점은!
저도 학부연구생으로 혼자 코드를 작성해보면서 ML 프로젝트를 해볼 때,
코드가 조금 난잡하다는 인상을 받았습니다.
그 이유가 바로 이런 함수와 클래스와 같은 코딩 자체의 최적화를 높인 것인데요.
자주 쓰는 기능, 시각화, csv 파일 load와 같은 기능은
내가 익히 쓸 수 있도록 유틸 함수로 관리하는게 좋다는 걸
확실히 깨달았을 수 있었어요.
공부하면서 코드를 공유하기도하고 타인과 이야기도 나눠야할 떄면
어떻게 하면 남들이 보기도 편하게 할까를 고민하게 되는 시점이 오는데
이 부분을 해당 강의를 학습하면서 채워나가는 느낌이 들었습니다.

앞선 강의를 통해 조정한 데이터 프레임을 각각 머신 러닝을 해봤습니다.
이제 실제로 모델 결과를 추출해보고 인사이트를 내리면 되는데 실제로 수치로만 보니 감이 잘 안오죠?
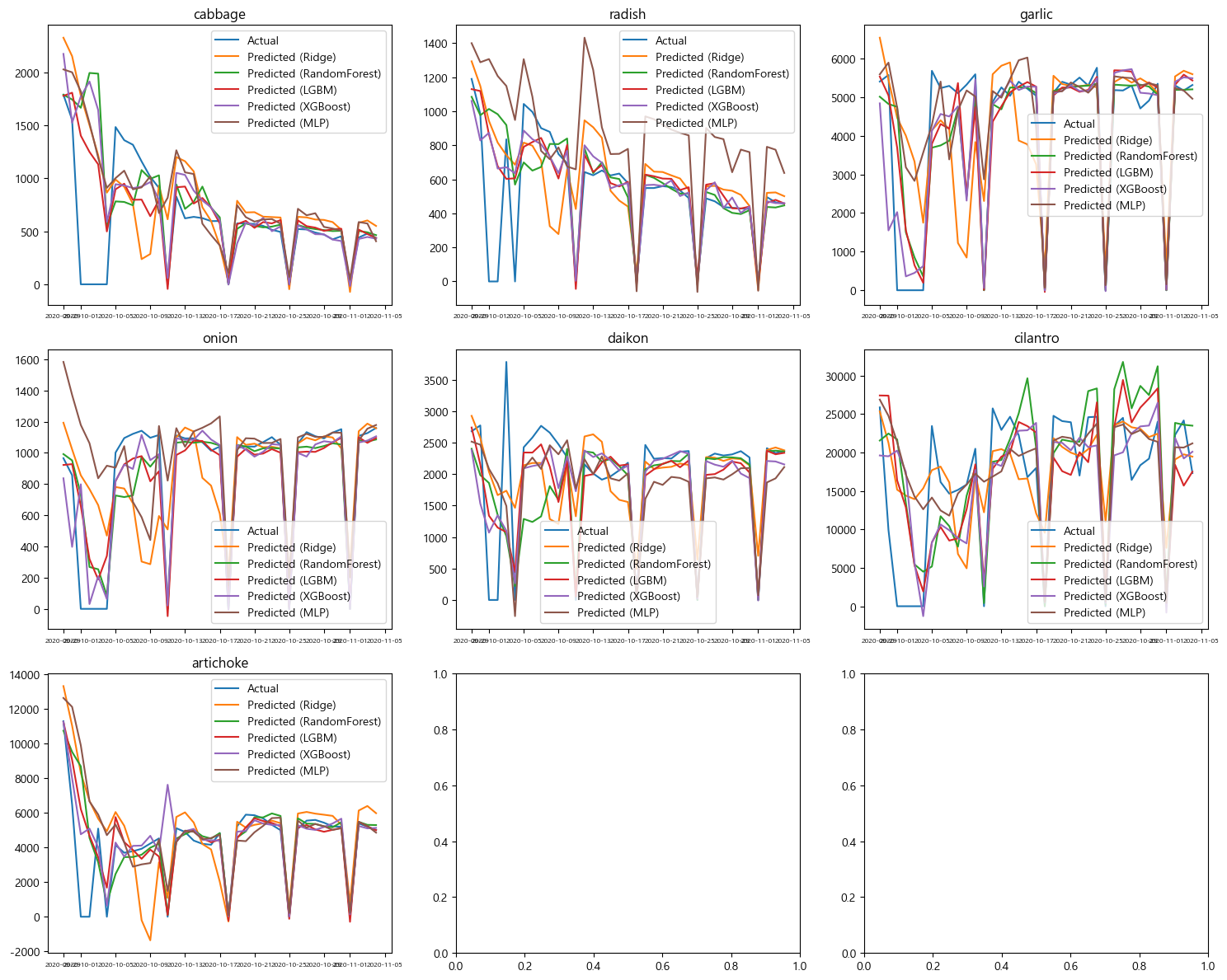
그럴 땐 역시
시각화를 통해 내 인사이트의 결론을 내리면 됩니다.
- prophet 보다 ML 모델이 좀 더 잘 맞는 것 같다는 느낌이 드네요
제일 중요한 건 이런 저런 모델과 사용해보고 평가 지표를 통해 제일 좋은 예측율을 보이는 것을 찾으면 되는 것 같아요.
특히 ML(머신 러닝) 분야는 제가 아는 얇은 지식으로선, 이런 모델 학습을 하고 나온 결과를 보며 파라미터를 조정하며
좀 더 잘 맞추는( FIT)한 모델로 내가 바꾸는 과정을 할 줄 알면 되는 것 같아요.
그럼 이제 제가 공부할 방향이 하나 새로 보이네요.
바로 평가 지표(MAPE, MSE, MAE, R^2 등) 원리와 의미 그리고 모델의 알고리즘을 학습해야할 것 같습니다.
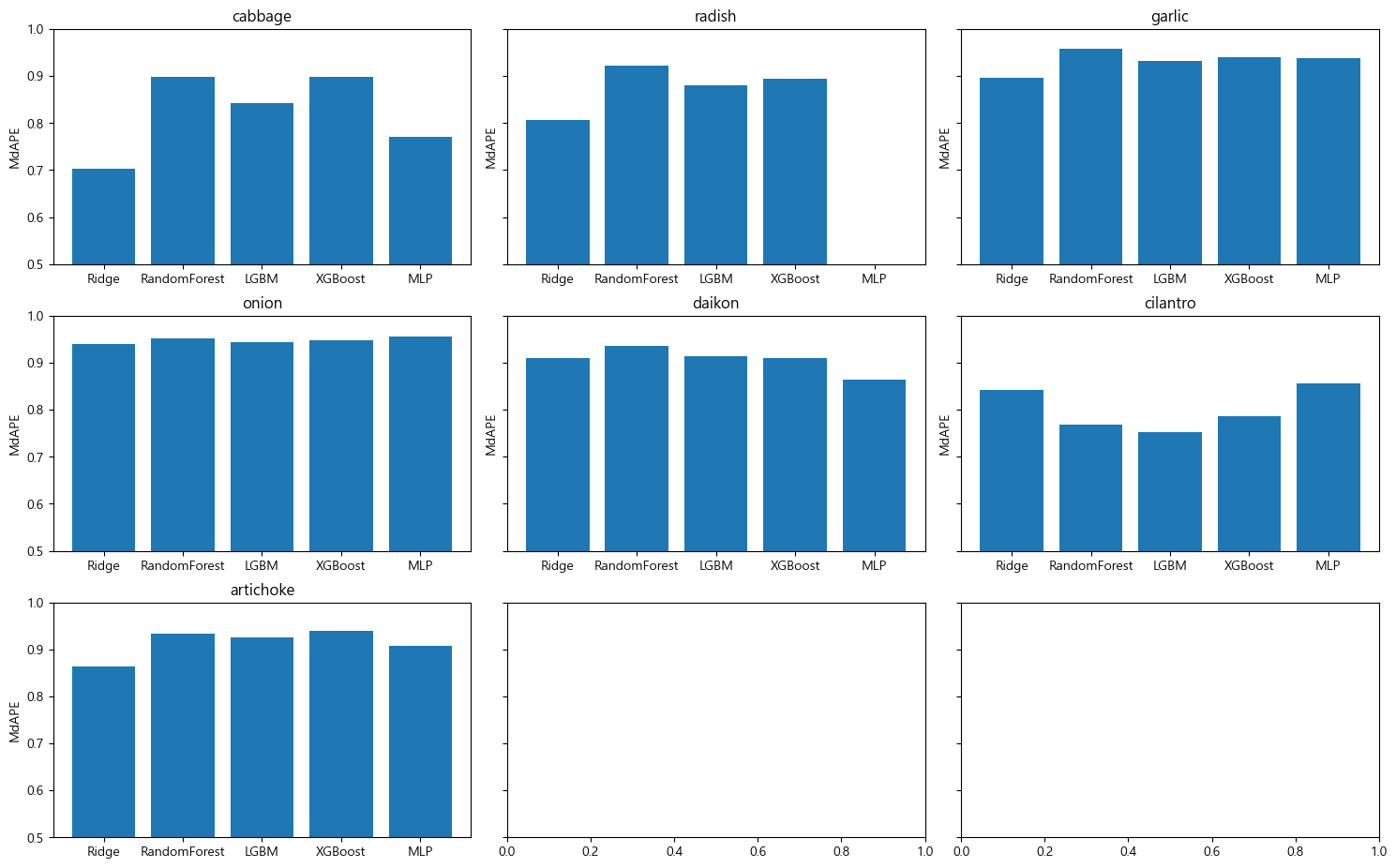
품목별로 모델을 무엇을 쓸지 차등 선택해야합니다.
꺳잎은 XGBOOST가 제일 높고 radish는 RF네요. 전체적으로 RF가 높은 것을 볼 수 있어요. (RF 짱..)
랜덤 포레스트가 무엇인지는 이후에 ML 공부를 상세히 하면서 기록해둘게요!
전공 수업과 여러 강의로 학습은 했는데 한 번 정리해둘 필요가 있겠네요.
간단히 정리 하자면 아래와 같습니다!
랜덤 포레스트(Random Forest)
- 의사 결정 나무 보다 작은 Tree를 모아서 값을 투표하여 결정하는 모델
- 의사결정 나무에서의 단점인 과적합의 문제를 해결할 수 있음
- 의사결정 나무보다 더 작은 나무(깊이가 낮은)여러 개를 모아 투표
- 몇몇 트리는 과적합이 발생할 수 있으나 다수의 트리를 기반으로 예측하기에 영향 감소
- 다수의 학습 알고리즘을 사용한 걸 앙상블학습이라고 함
Feature Importance Check
-영향도가 높은 피처를 확인하는 방법이에요!
- 성능에 큰 영향을 주지 않는 요인들과 큰 영향을 주는 요인들을 확인해봅시다!
import shap
target = 'artichoke'
model = XGBRegressor().fit(train_data[features], train_data[target])
explainer = shap.Explainer(model, train_data[features])
shap_values = explainer(test_data[features])
shap.summary_plot(shap_values, test_data[features], title="SHAP Summary Plot for 'cabbage'")
- 빨간색일수록 영향도 높아요.
- 오른쪽에 있으면 정비례 관계 피처
- 왼쪽으로 있으면 피처값을 낮추는 반비례 관계 요인임
이렇게 내가 ML을 돌리면서 실제 어떤 인사이트를 뽑고 또 피처값을 조정할지
결정하는 과정 까지 배울 수 있었네요.
더 공부해야할 것 까지 보이는 좋은 학습 시간이었습니다.
해당 목차까지 공부하는 것으로 2주차가 마무리됩습니다.
여러분도 한 번 해당 강의를 통해 데이터 사이언티스트로 성장해보심은 어떤가요?!
이상 메타코드 앰베서더 최승우였습니다~

'공모전 및 대외활동 > 앰배서더' 카테고리의 다른 글
| [데이터 사이언티스트] kaggle 데이터를 활용한 실전 머신러닝 | IT기업 Data Scientist 현직자 (5) (3) | 2024.10.26 |
|---|---|
| [데이터 분석 부트캠프] - 전액 환불/ 직장인 전용 파트타임 부트캠프 홍보 (5) | 2024.10.20 |
| [SSAFY 13기 모집] 마이스터고 졸업자도 SSAFY와 함께해요! (2) | 2024.10.13 |
| [SSAFY] SSAFY 13기 모집 (10.21~11.4)🙆♀대한민국 청년 누구나!🙆♂ (1) | 2024.10.13 |
| [데이터 사이언티스트] kaggle 데이터를 활용한 실전 머신러닝 | IT기업 Data Scientist 현직자 (3) (1) | 2024.10.11 |



